新智能引擎:基于思维链的强化学习
从 AlphaZero 到思维链强化学习
关键词,AlphaZero,Reasoning,CoT(Chain of Thought),RL(Reinforcement learning),Test-time Compute,Long2Short,Aha Moment
最近,DeepSeek R1 成为科技界热议的话题,但大部分人讨论的是训练成本,但我觉得其中更需要人们知道的是背后 Reasoning 模型的意义,于是整理了这篇内容,我并不是专业的创业人员,只是爱好者,如果有专业人士看到问题欢迎指正。
强化学习巅峰 AlphaZero 的启示
在回顾大模型发展的新动向之前,我们先将视线转回 2016-2017 年 DeepMind 的 AlphaGo 与 AlphaZero:
AlphaZero 的意义在于证明:一套通用强化学习算法,只要能自我博弈并对最终结果(胜负)进行评估,就能在封闭性且有明确评估准则(胜/负)的任务上取得极高水平。“自对弈”产生的数据持续反哺模型,形成正向循环,短期内便超越了人类甚至之前的专业 AI 系统。
自此到 GPT 兴起之前,强化学习一直占据人工智能领域的主流,并且在 GPT 出现后也有不少研究团队在探索 RL,但模型基座性能不足时这条路并未能走通。
GPT 训练范式的兴起与瓶颈
到 2023-2024 年间,基于GPT-3.5、GPT-4 等大语言模型的三阶段训练方式已广为人知:
- 预训练(Pre-Training):在海量无标注文本上进行语言建模;
- 监督式微调(STF):使用优质问答数据、指令数据等进行微调;
- 后训练(Post-Training):大量采用 RLHF(基于人类反馈的强化学习),通过人工标注、打分来“对齐”模型。
然而,RLHF 带来的对齐效果在一定程度上会让模型倾向于“安全、礼貌、政治正确”,这同时可能造成“对齐税”:模型在某些复杂推理场景下的思考深度与灵活性受到抑制。从各类评测基准看,当模型对安全性和可控性做更多妥协时,其逻辑思维和创造力往往会被“磨平”一些。
同时,预训练阶段的语料数据,训练数据枯竭,同时合成数据造成的污染,一直是困扰行业的难题,也制约模型性能提升。
传统 RLHF 在后训练阶段的巅峰大概是 Anthropic 的 Claude 3.5 这一模型。
思维链强化学习的崛起
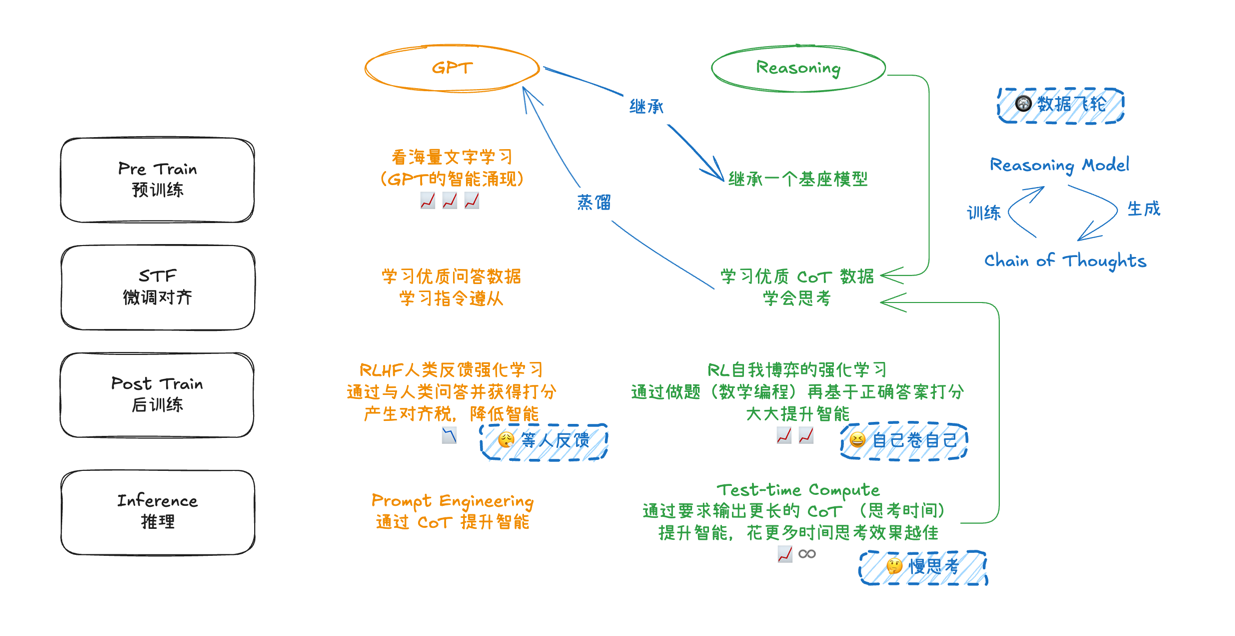
让模型输出思维过程:从 Prompt 到内在“自我纠错”
早期的“Let’s think step by step”Prompt(Chain of Thought, CoT)就显示了惊人效果:只要在提示词中加入这句咒语,模型就能输出更优异的回复。但那时的 CoT 还更多依赖人工编写 Prompt,并不意味着模型内部真的学会如何系统思考,也未能彻底解决数据来源稀缺的问题。
此后,人们开始探索:能否直接训练模型在回答客观、可验证对错的封闭性问题时,输出推理思维步骤,并让它依照“对错”结果进行强化学习? 也就是将 AlphaZero 思路应用到大语言模型上——自我对弈之处,变为“模型自己在做数学题、编程题,自己产生大量 CoT 答案并评估正误,进而持续迭代更新模型参数”。这被称为 CoT RL 或 Reasoning RL 的方法。
训练过程中的“数据飞轮”
在这种自我强化学习中,模型会输出一条条 CoT:“犯错—纠错—再前进”的过程被完整记录,并通过最终答题结果来给出正或负奖励。因为不再严格依赖人工标注,数据不会枯竭——越好的模型产生越优质的思路,训练出更强模型,再反过来生成更好数据,形成正反馈循环,正如当年 AlphaZero 自我对弈那样。
RLHF vs CoT RL
RLHF:通常用人工标注或人工反馈打分,数据昂贵且容易产生“对齐税”;
CoT RL:利用客观题(如数学、编程)自判正误,极大提升训练规模与深度,同时使模型在思维链生成和自我纠错方面更为主动。这种自由思考被认为是真正的“推理能力”的培养,而不只是对齐。
关键时间线:2024 年后“大模型”竞赛与转向
下面梳理 2024-2025 年与此相关的重要事件,帮助我们理解 CoT RL 的崛起脉络:
2024年7月15日,OpenAI “Strawberry” 传闻流出,被认为是对 CoT RL 实验成功的内部代号。
2024年9月12日,OpenAI 发布 o1-preview 与 o1-mini(后者通常被视作蒸馏版本)。
2024年11月20日,DeepSeek 发布 R1-Lite,暗示其在高级推理方面也有进展;次日阿里巴巴发布 Macro-o1,Qwen 发布 QwQ-32B-Preview 等。
2024年12月5日,OpenAI 用 o1 替换 o1-preview 并推出 o1 Pro,已准备好模型可运行在“更长推理时间”模式。
2024年12月14日,Ilya(OpenAI 联合创始人)在演讲中说:“Pre-Training as we know it will end”,此时主流媒体解读为模型性能已经到达瓶颈点。
2024年12月20日,OpenAI 宣布性能远超 o1 的 o3 模型,并开放早期使用申请;Google 同日发布 Gemini 2.0 Flash Thinking(外界猜测是其内部“大模型推理蒸馏”版本)。
2025年1月20日,DeepSeek 发布 R1,Kimi 也发布了 kimi-1.5。这两家机构的技术报告明确展示如何在“大模型+CoT+RL”上实现自我迭代训练,标志着 reasoning model 重现方法 已几乎“被说明白”。
从这一连串事件可见:大型研究机构与顶尖公司几乎在同一时期转向“CoT RL”。OpenAI 的 o1、o1-pro 以及后续的 o3 都在强化“长推理”和“推理时间可调”的理念,Google 的 Gemini 2.0 Flash 系列也被认为采用了类似技术,只是未公开细节。
Test-Time Compute:训练结束后还能靠“思考时长”变强
在 Reasoning 模型中涌现出来的能力 Test-Time Compute——即在推理阶段(inference phase),允许模型花更多计算时间生成更长的 CoT,从而获得更高智能表现。它与传统的“只在训练阶段投入算力”截然不同:
Adaptive Compute:当问题简单时,模型可以快速作答;当问题困难或需要更深入思考时,模型可以生成更多 Token(即更长的思维链),就像一个人多花时间思考更复杂的问题。
灵活付费与资源消耗:对于企业或用户而言,现在推理不仅是一次性费用,还可能根据需要花“更多推理算力”来获得更高质量与更深入的思考结果。这可能让 GPU 从训练阶段极大需求,转向到推理服务阶段。
与 RL 策略相结合:模型在产生一长串 CoT 的过程中,会自发检验、纠错,从而让最终答案更加稳健。这种在推理阶段的“动态优化”也进一步加深了模型的表现。
这就解释了OpenAI o1-pro 提供“多档思考时长”并引入“reasoning_effort”等参数的做法。站在产品角度,这是一种全新方案:花更多时间、多生成一些中间推理 Token,就可以“买到”更高的准确度或更深层次的答案。
“预训练时代将终结”与新一波智能爆发
结合以上线索,人们逐渐看清:
Reasoning 训练是一条 GPT 后的全新 Scaling 途径:其核心在于摆脱标注依赖,通过自我生成数据训练“深度推理”能力。
飞轮会越来越快:强模型 → 产生更优 CoT → 再训练得到更强模型 → 进一步迭代;同时推理端可以“花时间”来换取思考深度。
对算力的需求将更持久且更庞大:过去主要在训练阶段用 GPU,如今还要在推理时付出额外算力;要解决更高级的逻辑/编程/数学任务,就需更多推理 Token。
预训练不再是唯一瓶颈:Ilya 提出“Pre-Training as we know it will end”,就是因为未来大模型将更多倚赖后训练(Post-Train)与推理阶段(Test-Time)的计算来进一步提升智能;传统大规模语料预训练只负责“语言理解基础”,而真正的推理与思考能力更多来自后续的自适应计算。
这也解释了 Sam Altman 提出的 ASI(Artificial Super Intelligence)“近在眼前”——至少在逻辑推理与封闭性任务上,随着自我博弈式的训练方法兴起,模型的能力正快速迭代到人类难以企及的程度。当然,其跨领域泛化水平还有待观测,但如今我们已看到强烈信号:AlphaZero 式的“自我学习”一旦在通用大模型上开花,想象空间会十分巨大。
结语
从 2016 年的 AlphaGo,到 2017 年的 AlphaZero,再到 2024 年开始集中爆发的 “CoT RL” 思路,深度学习与强化学习不断演进,正试图破解更多原本高度依赖人类“高阶认知”的领域。当“后训练”与“自我推理”结合在一起,模型就有了自我纠错和数据自循环的能力,能够在复杂任务上迭代逼近更高水平。
或许,正如文中多位研究者所暗示的那样:如果“链式思考 + 自我训练 + RL 后训练”仍能复刻 AlphaZero 那般飞速迭代的曲线,AGI/ASI 的到来将可能比我们想象得更快。
参考内容
以下是我整理这篇内容的过程中帮助很大的信息源
- gwern 的评论: https://www.lesswrong.com/posts/HiTjDZyWdLEGCDzqu/implications-of-the-inference-scaling-paradigm-for-ai-safety?commentId=MPNF8uSsi9mvZLxqz
- kimi 研究员 Sung 对自家技术报告的补充说明: https://www.zhihu.com/question/10114790245
- 知乎网友 hijkzzz 整理的关于 reasoning 的大量公开材料: https://github.com/hijkzzz/Awesome-LLM-Strawberry
注,这篇内容中我使用 grok 进行信息收集确认,使用 notebooklm 进行研究报告整理汇总,使用 o1pro 进行对草稿进行内容整理串联。
- Previous: 2024 我重度使用 AI 的一年
- Next: 中国大模型的安卓时刻